GlossaGen
Large Language Models go Chemistry! As part of the global LLM Hackathon for Applications in Chemistry and Materials Science, our team (Dieter Plessers, Philippe Schwaller and me) built a tool to automatically generate glossaries from any PDF, in particular scientific publications, as a tool to help scientists create effective proposals. In a case study that we set up during the two-day hackathon, we investigated publications on Zeolites and were excited to rediscover common relations in that area of chemistry. On a technical level, we built a simple large language model agent to parse text from a publicatin and systematically identify and define keywords of relevance. We even began to set up a LaTeX extension to create a glossary simply by the command \printglossary (just like \printbibliography).
As a “cherry on top”, we created a tool to extract and link keywords in the publication via a knowledge graph. Neo4J awarded us with the Knowledge Graph Prize, as outlined in a recent newsletter issue here.
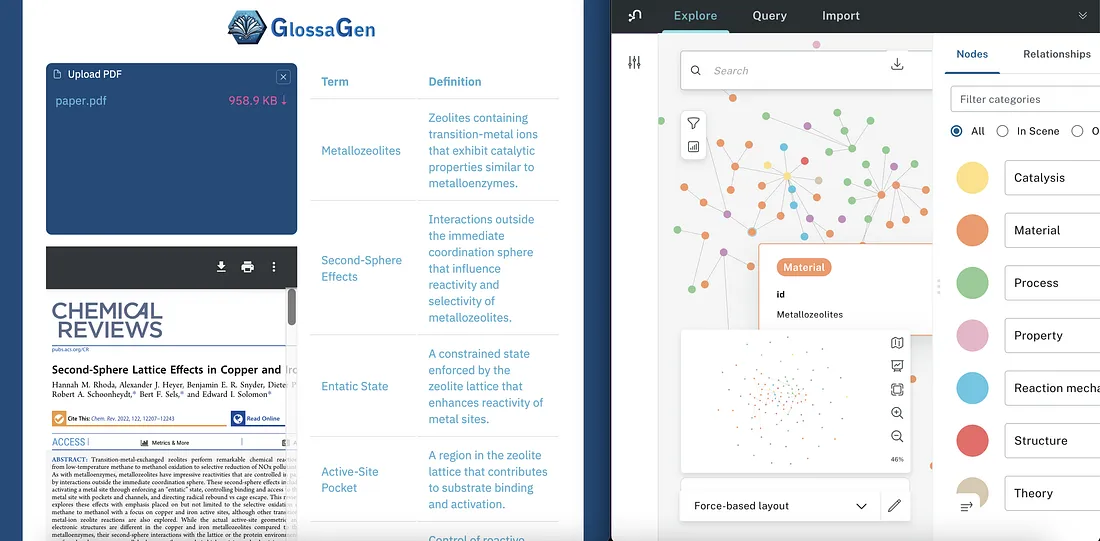
We are honored that our project headlined the medium post on “How to Use LLMs to Accelerate Scientific Discovery” by Ben Blaiszik! A preprint of the work of all fantastic teams is in preparation. We thank all organizers for setting up such a fantastic hackathon experience.
Check out our project on GitHub here.